In a microservices architecture, the number of server to server connections increases dramatically compared to alternative setups. Interactions which would traditionally have been an in-memory process in one application now often rely on remote calls to other REST based services over HTTP, meaning it is more important than ever to ensure these remote calls are both fast and efficient. Let’s look at the lifecycle of an HTTP connection and how Connection Pooling can help!
The HTTP Connection Lifecycle
Usually when talking about a HTTP call, only the orange section is thought about. A client sends a request to an endpoint, describing what data is being requested, the server processes this request and sends back the data in a response. However it’s clear to see a lot more is happening, most importantly each time the arrows change directions latency will be measurable (even if small).
 DNS Resolution
DNS Resolution
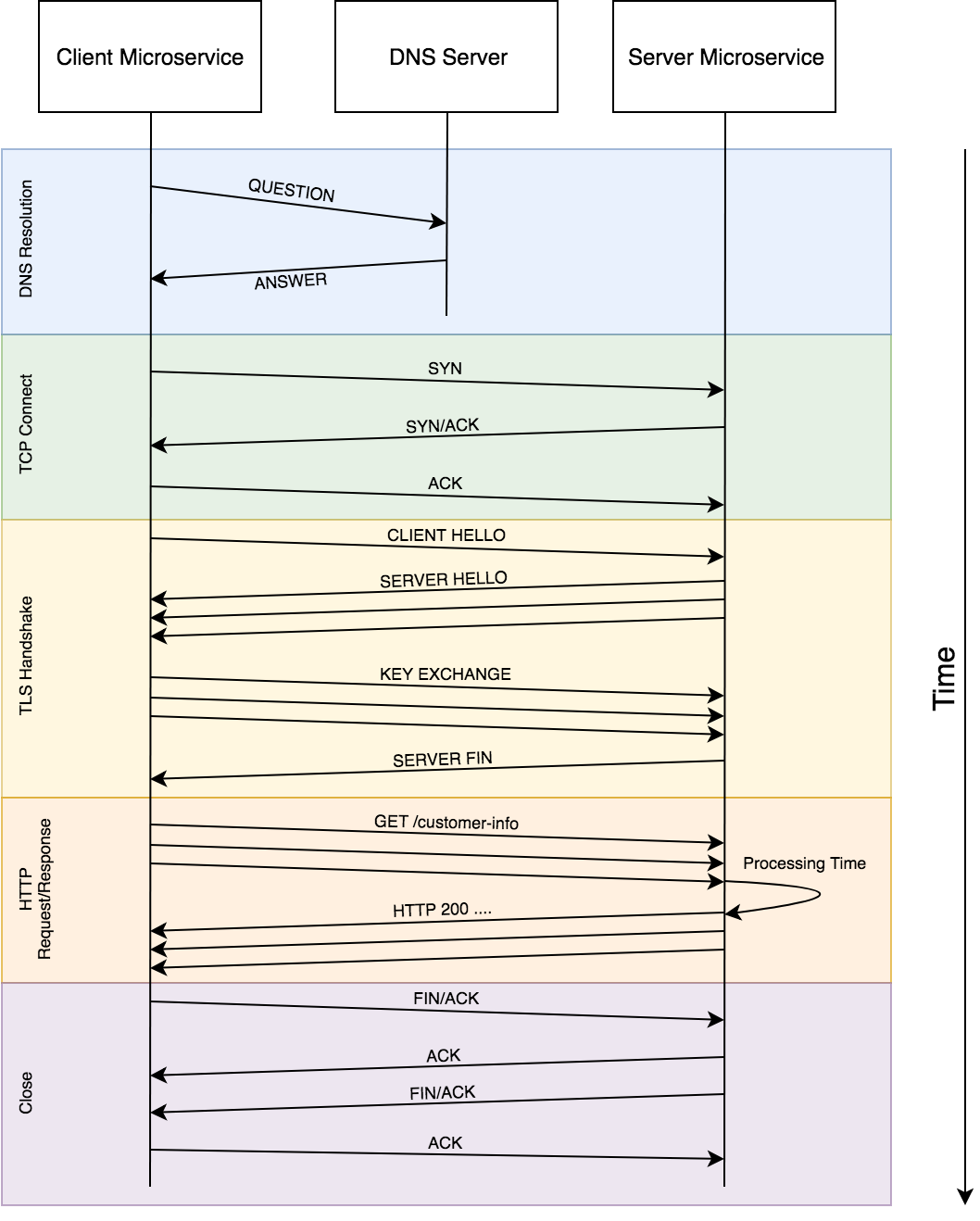
When calling another service, it usually has some kind of hostname (e.g. svc.testingsyndicate.com). In order to call this service, this hostname needs to be resolved into an IP address (think of this like looking up a phone number for a business name).
DNS resolution typically happens over the UDP transport, I won’t go into detail on this here, but it means there is no handshake necessary between the client and the DNS server and instead the request can just be sent and then wait for the response.
TCP Connect
For data to flow between a client and server, the TCP handshake needs to occur. This handshake is used to initialise values which are later used to ensure reliability in the data exchange. This enables checks to take place which ensure that data is being received intact and without errors, and allows for retransmissions to occur if there are any problems. Once this handshake is completed the connection is said to be in an “established” state.
TLS Handshake
If you are securing your connections with TLS, then a TLS handshake occurs next. This handshake is much more heavy weight than the TCP handshake. Fairly large pieces of data need to be transferred between client and server such as the certificate being used by the server, and in Mutual TLS (client certificate authentication) the client certificate also needs to be sent to the server. Cryptographic functions need to be executed at each time which can be CPU intensive and also block if there is a lack of “entropy” available.
Once the TLS handshake is completed, the actual HTTP request can now be sent.
HTTP Request/Response
This is the part that we are actually bothered about most of the time. The client sends a request (containing elements such as the HTTP method and path, along with any request headers and a body if required). The server receives this requests, processes it however it needs to, and sends the response (containing a status code, headers and body). The client can then parse this response to obtain the data requested.
Close
As we started this conversation with a handshake, we now need to say goodbye to the server and close the connection. Again this is a 3 way handshake similar to the start of the conversation.
So.. Connection Pooling?
Connection Pooling is a feature available in a number of HTTP Client libraries, so how does it work?
Conceptually, this is actually quite simple. Taking an example of 2 requests made back to back, the first request will proceed as normal through the lifecycle shown above, until it gets to close the connection. When connection pooling is in use, instead of closing the connection it will instead be put to one side for use later. When a second request then needs to be made to the same host it can skip DNS resolution, TCP connect and TLS handshake, and just reuse the connection we put to one side earlier.
Configuration
Connection pooling libraries usually comes with a few common parameters and it’s key to set them correctly.
| Parameter | Description | Notes |
|---|---|---|
| Max Connections | Maximum number of connections that can be used in the pool at once | Possibly the most important parameter in a pool. Too high will needlessly hold on to too many connections and could cause resource contention issues with other services.
Too low and requests won’t be able to get through and cause a bottleneck (possibly worse than no pool at all) Set to a value that’s high enough to cover your normal load plus some room for peaks. |
| Minimum Connections | Minimum number of connections to be kept in the pool | A less common parameter, but allows some pools to open connections ahead of time so they are ready for use immediately. |
| Time to Live / TTL / Max Age | Maximum time to keep a connection alive before closing it for real | Often set to infinity on many pools, but can be important to set. Particularly if the service you are connecting to uses DNS round robin for load balancing, or DNS for blue/green deployment.
Failure to set this, or setting it too high could mean your service will continue to use a host that is being decommissioned or overloaded. Setting it too low will reduce any positive effects of the pool. |
| Connection Request Timeout / Max Backlog | When all connections up to “Max Connections” are already in use, how long to wait for one to become free. Or how long a backlog can become waiting for free connections. | These 2 parameters are 2 different ways of trying to stop the pool from becoming overloaded. Often the defaults for these settings mean that enormous backlogs can grow which can affect future requests from completing in a timely manor. Some testing will need to done to find the best values |
Testing Considerations
This wouldn’t be TestingSyndicate without testing considerations.
- Take baseline performance readings before and after applying connection pooling and between any configuration changes to the pool
- Record metrics from the pool if possible (such as how many connections are being used and how large the backlog is for any given load applied) to see how close to the configured limits you are. Calculate and test out capacity limits of the pool and check these against your production workloads.
- Ensure testing is carried out for both successful and failure scenarios (such as timeouts from varying percentages of upstream calls), how is performance affected in these scenarios?
- If your upstream components add or modify DNS records as part of their scaling or deployment processes, test your integration with them and ensure that your applied load is being balanced effectively. Ensure that migration to new upstream component backends completes within an acceptable time
For the common Apache HttpComponents HttpClient, TestingSyndicate provide the HcJmx library to export Connection Pool metrics (available on maven central). It will require a code change to enable the metrics in your services, however these metrics are also highly valuable in a monitoring capability outside of running tests.